操作系统
概念
操作系统是一个大型的程序系统,它负责计算机的全部软硬件的分配、调度工作,控制并协调多个任务的活动,实现信息的存取和保护。它提供用户接口,使用户获得良好的工作。
作用
作为用户与计算机硬件系统之间的接口
- 命令方式
- 系统调用方式
- 图形,窗口方式
作为计算机系统的资源的管理者
- 处理器
- 存储器
- I/O设备
- 信息(数据和程序)
用作扩充机器,实现资源的抽象
- 把覆盖了软件的机器称为扩充机器或虚拟器
- 包含了若干个层次,因此在裸机上覆盖OS后,便可获得一台功能显著增强,使用极为方便的多层扩充机器或多层虚拟机
- 隐藏设备操作的实现细节,向上提供一个抽象的接口
目标
- 有效性(改善资源利用率,提高吞吐量)
- 方便性(配置OS后计算机系统更容易使用)
- 可扩充性(层次化结构)
- 开放性(遵循世界标准规范)
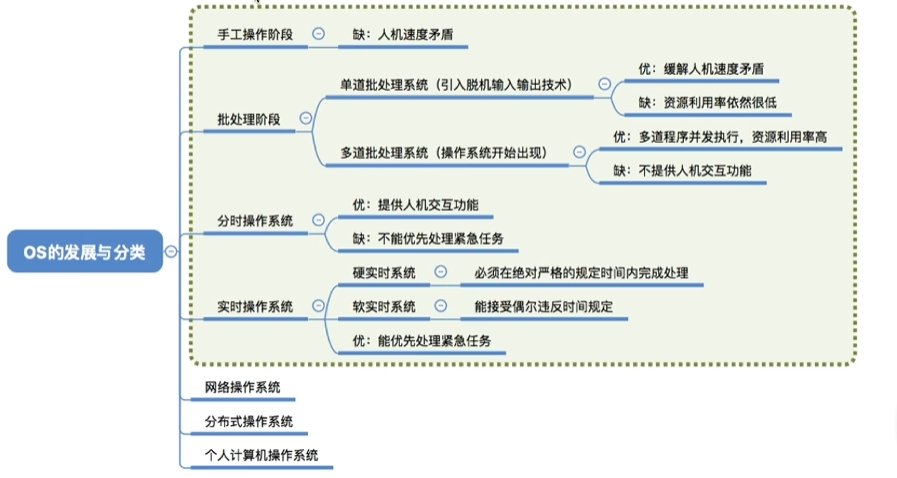
发展历程
产生
- 手工操作阶段
- 单道批处理阶段
形成
- 多道批处理
- 分时系统
- 实时操作系统
发展
- 微机操作系统
- 多处理机操作系统
- 网络操作系统
- 分布式操作系统
- 嵌入式操作系统
基本特性
- 并发
- 共享
- 虚拟
- 异步性
基本功能
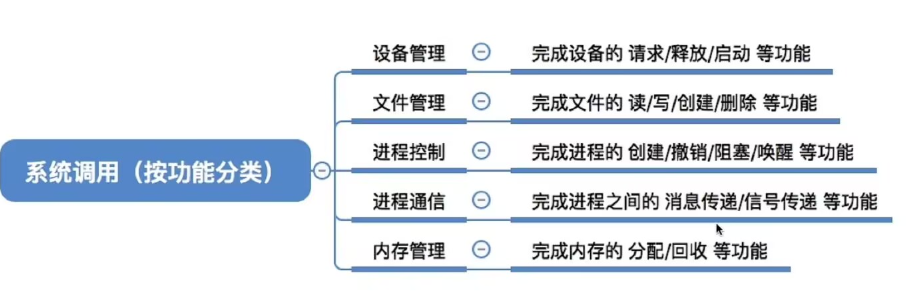
- 处理机管理:进程控制,进程同步,进程通信,调度(作业调度和进程调度)
- 存储器管理:内存分配,地址映射,存储保护,存储扩充
- 设备管理:设备分配,设备驱动,缓存管理,设备独立性和虚拟设备
- 文件系统管理:文件存储空间管理,目录管理,文件的读写功能和存取控制
- 用户接口:命令接口,程序接口,图形接口
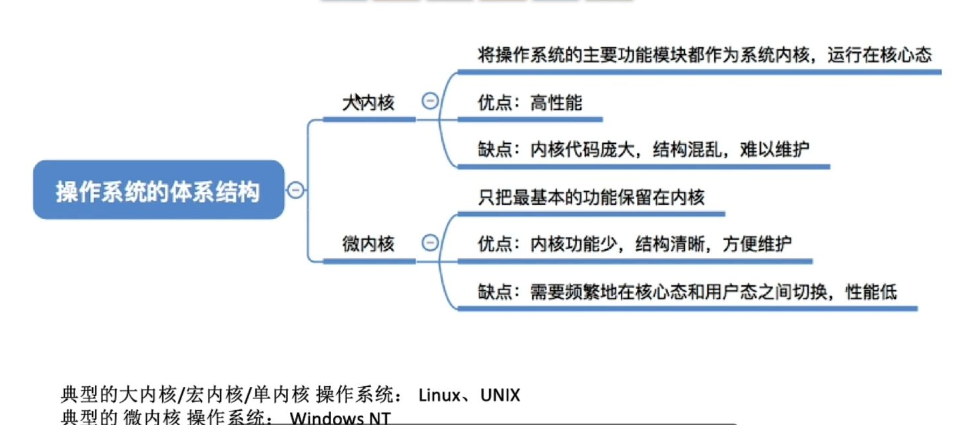
结构设计
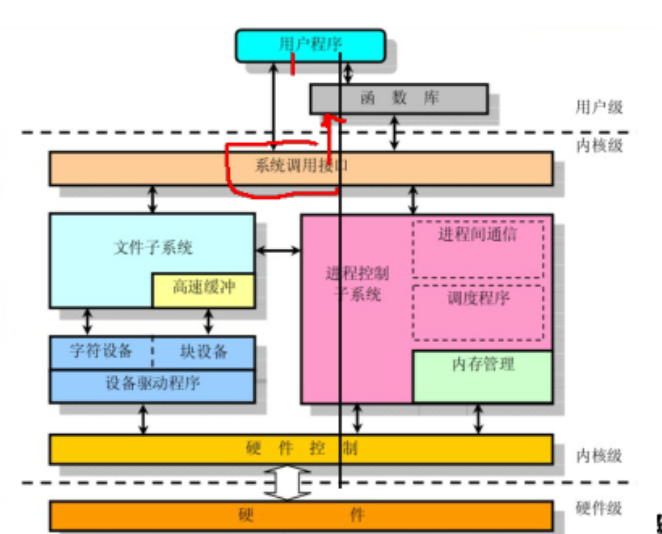
系统调用
又称广义指令,它是由操作系统向程序提供的程序接口,用户只能通过程序简介的使用这些接口。
- 与库函数不同,与一般的过程调用不同,属于系统时间
进程
基础
程序的顺序执行与并发执行
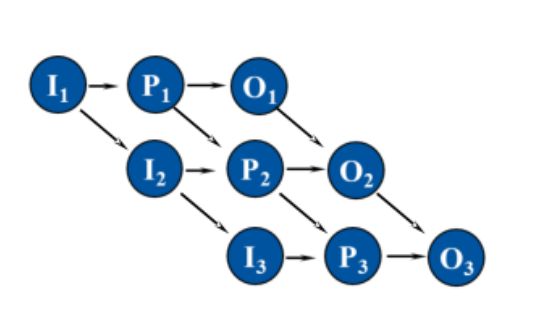
前趋图是一个有向无循环图,记为DAG,可用于描述程序/进程之间执行的前后关系.
结点、有向边、直接前趋、直接后继、初始结点、终止结点,重量
无循环关系可实现顺序执行
在计算机系统中只有一个程序在运行,这个程序独占系统中所有资源,其执行不受外界影响。一道程序执行完后另一道才能开始。
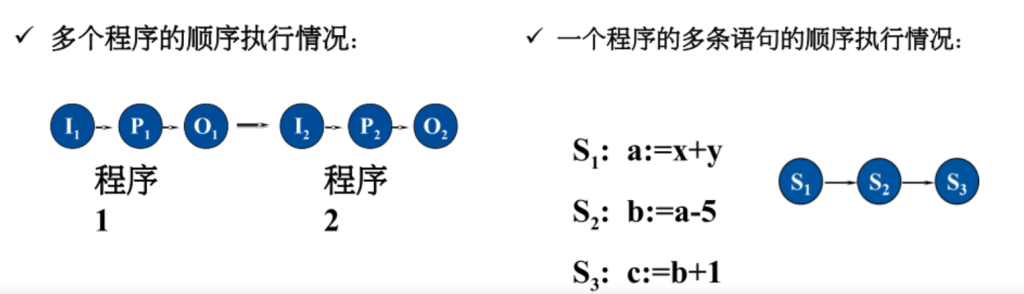
程序顺序执行的特点
顺序性:一个程序开始执行必须要等到前一个程序已执行完成。
封闭性:程序一旦开始执行,其计算结果不受外界因素影响
可再现性:程序的结果与它的执行速度无关(即与时间无
关),只要给定相同的输入,一定会得到相同的结果
程序的并发执行
若干程序同时在系统中执行,这些程序的执行在时间上是重叠的,一个程序的执行尚未结束,另一个程序的执行已经开始。

间断性
失去程序的封闭性
程序在并发执行时,是多个程序共享系统中的资源,因此这些资源的状态将由多个程序来改变。
不可再现性:执行结果不可再现
并发性:多个进程可同存于内存中,能在一段时间内同时运行
进程的状态及转换
不同系统设置的进程状态数目不同。
进程的三状态模型
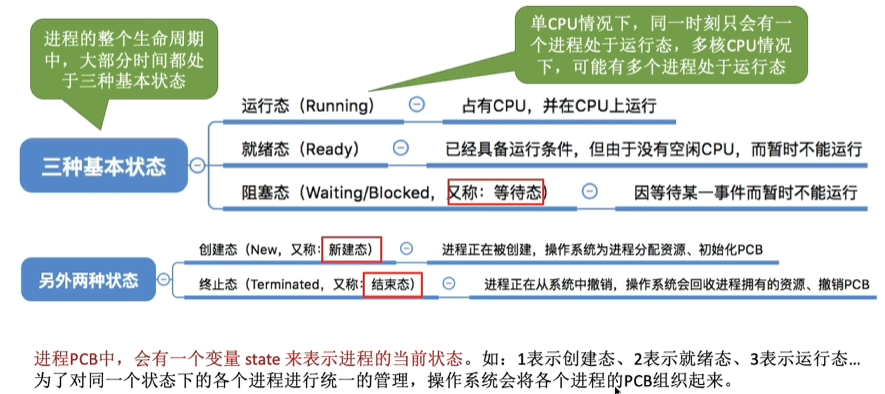
- 进程在生命消亡前处于且仅处于三种基本状态之一
- 就绪队列:所有处于就绪状态的进程所在的队列。
单处理机系统一个进程处于运行状态
多处理机系统有多个进程处于运行状态阻塞队列:系统根据阻塞原因设置多个队列来管理处于阻塞状态的状态的进程
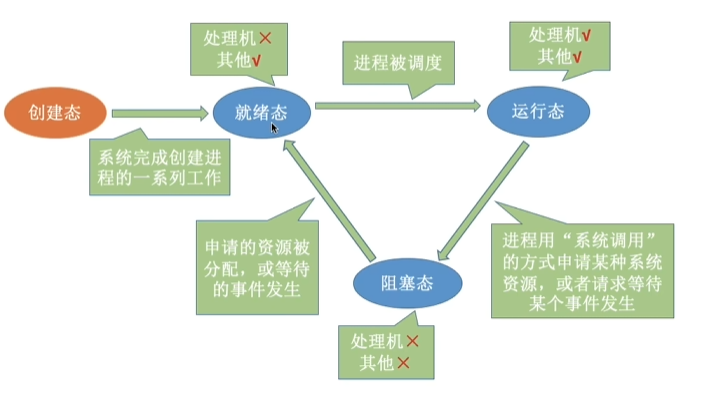
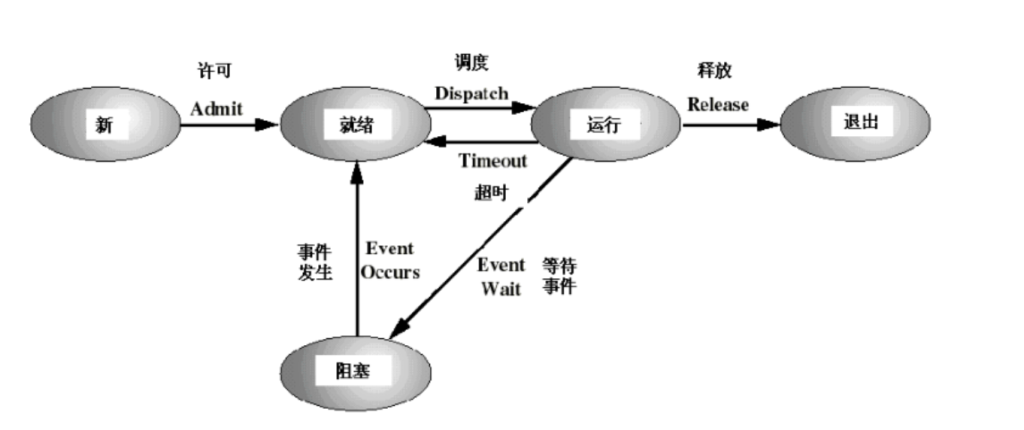
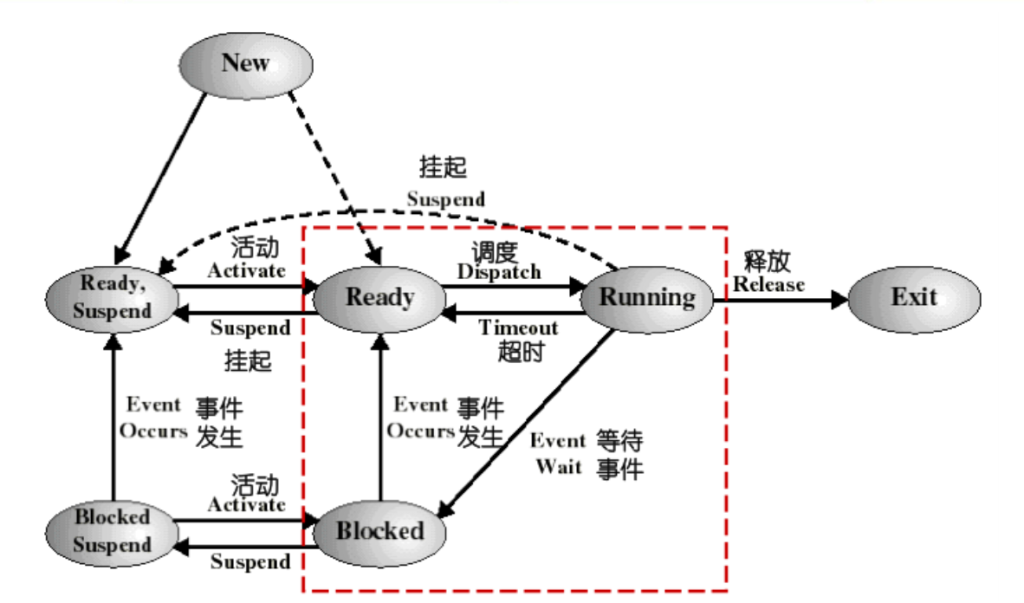
七状态进程模型
引入挂起状态的原因:
- 终端用户的请求
- 父进程请求
- 负荷调节的需要
- 操作系统的需要
- 对换的需要
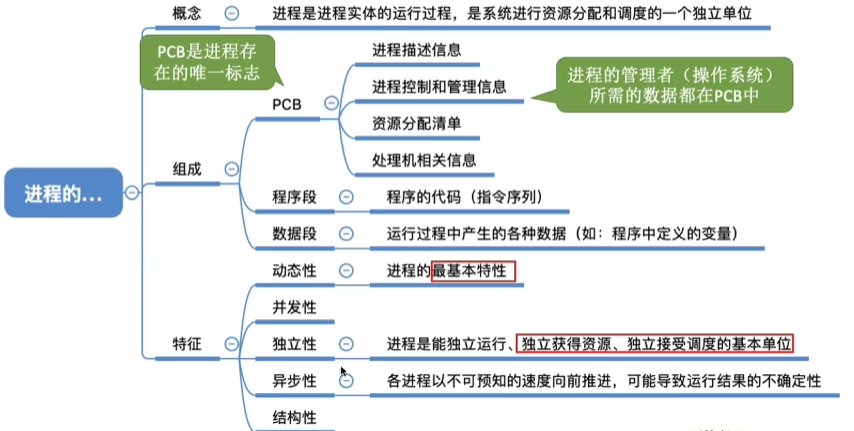
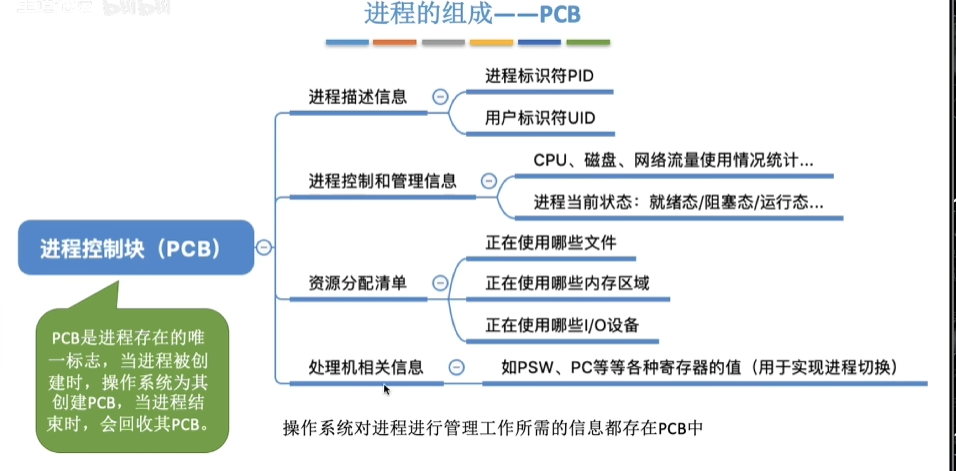
进程控制块
为了描述和控制进程运行,系统为每个进程定义了一个数据结构,称为进程控制块(PCB】。
PCB中记录了OS所需的、用于描述进程当前情况以及控制进程运行的全部信息。
进程与PCB是一一对应的,PCB是OS感知进程存在的唯一标志。
PCB的作用
- 作为独立运行基本单位的标志;
- 能实现间断性运行方式;
- 提供进程管理所需要的信息;
- 提供进程调度所需要的信息;
- 实现与其他进程的同步与通信。
PCB的内容
进程描述信息:
- 进程标识符(processID),唯一,通常是一个整数
- 进程名称,通常基于可执行文件名
- 用户标识符(user ID);进程组关系
进程控制信息:
当前状态 运行统计信息(执行时间、页面调度)
优先级(优先级) 进程间同步和通信
代码执行入口地址 阻塞原因
程序的外存地址 进程的队列指针
进程的消息队列指针
所拥有的资源和使用情况:
- 虚拟地址空间的现状
- 打开文件列表
CPU现场保护信息:
- 寄存器值(RISC的通用、程序计数器PC、程序状态字PSW,地址包括栈指针)
- 指向赋予该进程的段/页表的指针
PCB表
系统把所有进程的PCB组织在一起,并把它们放在内存的固定区域,就构成了PCB表。
PCB表的大小决定了系统中最多可同时存在的进程个数,称为系统的并发度。
相同状态的进程PCB组成一个链表,不同状态对应多个不同的链表
就绪链表、阻塞链表
相同状态的进程,设置一个PCB索引表,存放这些进程PCB在PCB表中的地址。
进程控制
进程控制是对系统中的所有进程实施管理。
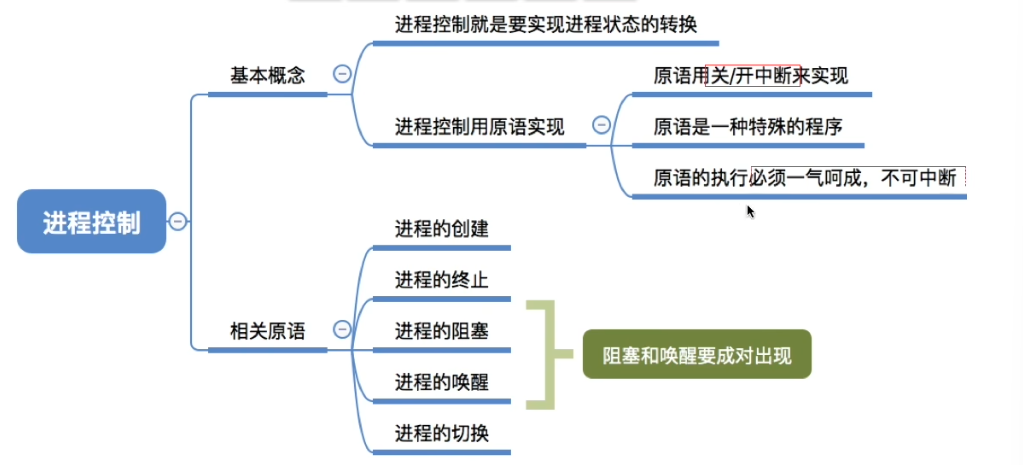
进程控制一般由OS内核的原语来实现
OS内核
通常将OS中一些与硬件紧密相关的模块 诸如中断处理程序、各种常用设备的驱动程序 以及运行频率较高的模块(时钟管理、进程调度)以及许多模块公用的一些基本操作)都安排在紧靠硬件的软件层次中,并使它们常驻内存,以提高OS的运行效率,并对它们受到特殊的保护。这部分就是操作系统的内核。
不同操作系统的内核包括功能不同,但都包括:
- 支撑功能
- 中断处理:内核最基本的功能
- 时钟管理
- 原语操作:内核完成一些操作,如进程控制。
- 资源管理功能
- 进程管理:全部或大部分放入内核
- 存储器管理
- 设备管理
内核中的原语(原子性)
原语是一种特殊的系统功能调用,它可以完成一个特定的功能,其特点是原语执行时不可被中断。
常用的进程控制原语:
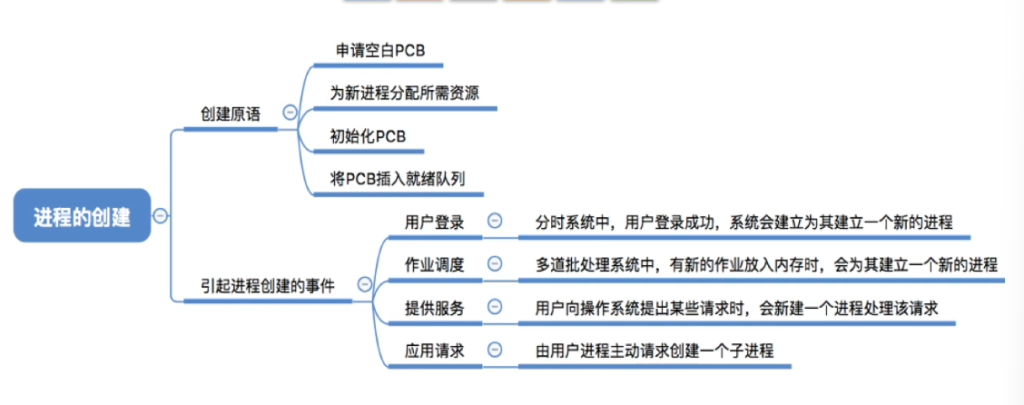
- 创建原语
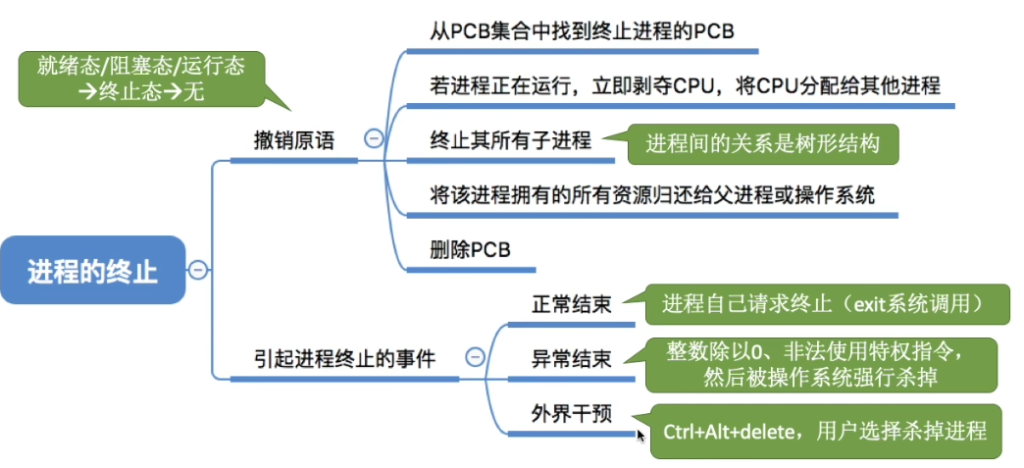
- 终止原语销毁
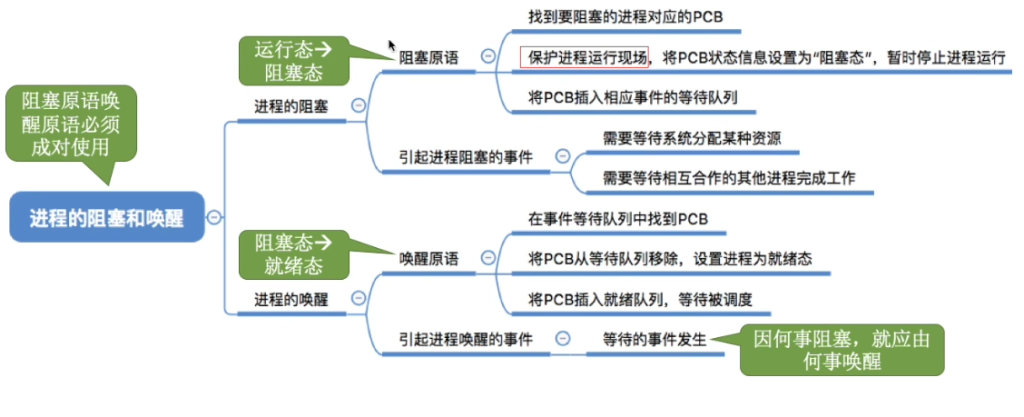
- 阻塞原语Block、唤醒原语Wakeup、
阻塞:当一个进程所期待的某一事件尚未出现时,该进程调用阻塞原语将自己阻塞。
进程阻塞是进程的自身的一种主动行为。
唤醒:当被阻塞进程所期待的事件出现时,则由有关进程调用唤醒原语将该进程唤醒。
处于阻塞状态的进程是绝不可能叫醒自己的,它必须由合作进程用唤醒原语唤醒它。
- 挂起原语Suspend、激活原语Active
进程的挂起与激活
- 挂起:将进程从内存移到外存,状态变为静止
- 激活:将进程从外存调回内存,状态变为活动
- 与阻塞的区别:挂起涉及内存-外存交换,阻塞只在内存中
进程同步
进程间的制约关系
- 间接相互制约(互斥关系):
- 源于共享系统资源(临界资源)
- 进程间相互竞争资源
- 如:多个进程争用打印机
- 直接相互制约(同步关系):
- 源于进程间合作
- 进程间相互等待、传递信息
- 如:生产者-消费者问题
临界资源与临界区
- 临界资源(Critical Resource):一段时间内只允许一个进程访问的资源
- 硬件:打印机、磁带机
- 软件:共享变量、数据、表格、队列
- 临界区(Critical Section):进程中访问临界资源的那段代码pseudocode复制下载repeat entry section; // 进入区:检查能否进入临界区 critical section; // 临界区:访问临界资源 exit section; // 退出区:释放资源,允许其他进程进入 remainder section; // 剩余区:其他代码 until false
同步机制应遵循的规则
- 空闲让进:没有进程在临界区时,应允许一个请求进程进入
- 忙则等待:已有进程在临界区时,其他试图进入的进程必须等待
- 有限等待:等待进入临界区的进程应在有限时间内进入
- 让权等待:进程不能进入临界区时,应立即释放CPU(避免忙等)
- 注意:整型信号量违反此原则,记录型信号量遵循此原则
硬件同步机制(低级同步方法)
Test-and-Set指令
boolean TS(boolean *lock) {
boolean old;
old = *lock;
*lock = TRUE;
return old;
}
// 使用TS实现互斥
do {
while TS(&lock); // 忙等
critical section;
lock = FALSE;
remainder section;
} while(TRUE);缺点:忙等待,浪费CPU
Swap指令
void swap(boolean *a, boolean *b) {
boolean temp;
temp = *a;
*a = *b;
*b = temp;
}
// 使用Swap实现互斥
do {
key = TRUE;
do {
swap(&lock, &key);
} while (key != FALSE);
critical section;
lock = FALSE;
remainder section;
} while(TRUE);缺点:同样存在忙等待问题信号量机制
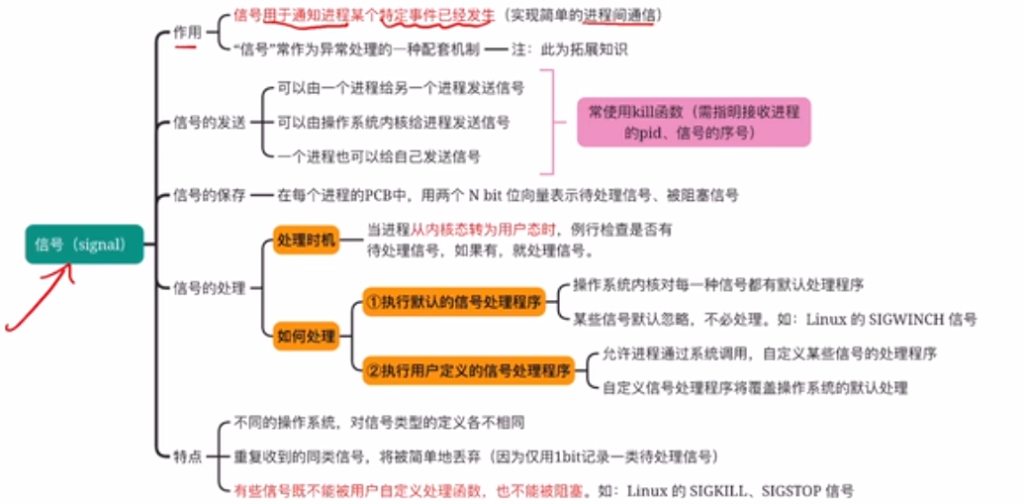
信号
用于通知进程某个特定事件已经发生。进程收到一个信号后,对该信号进行处理。
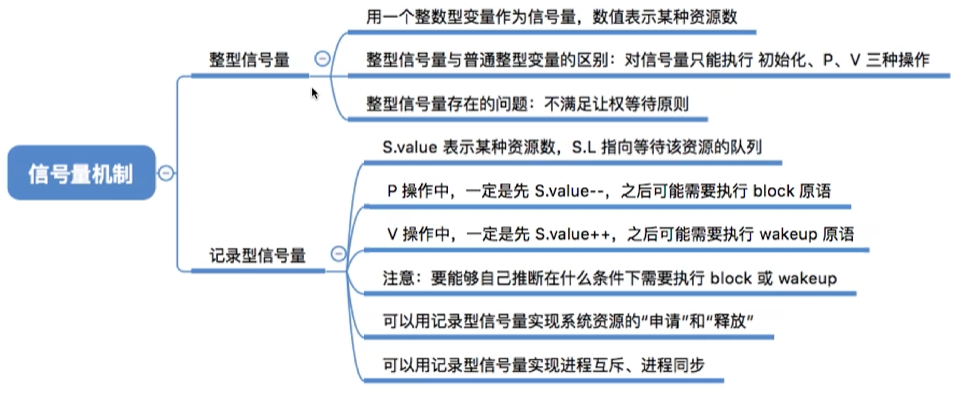
信号量机制
整型信号量(Dijkstra最初提出)
wait(S): // P操作
while S ≤ 0 do no-op; // 忙等如果资源数不够,就一直循环等待
S := S - 1;//如果资源够,占用一个资源
signal(S): // V操作
S := S + 1;//在退出区释放资源问题:违反”让权等待”原则,进程忙等
记录型信号量(真正实用的信号量)
typedef struct {
int value; // 资源计数,初值表示资源数量
struct process *queue; // 等待该资源的进程队列
} semaphore;
P(semaphore *s) { // P操作,申请资源
s.value--;
if (s.value < 0) { // 资源不足,阻塞进程
// 将当前进程插入s->queue;
block(); // 阻塞原语
}
}
V(semaphore *s) { // V操作,释放资源
s.value++;
if (s.value <= 0) { // 有进程在等待
// 从s->queue中移出一个进程P;
wakeup(P); // 唤醒原语
}
}关键理解:
value初值:可用资源数量value > 0:可用资源数value = 0:无可用资源,无等待进程value < 0:|value| = 等待进程数
Swait(S1, S2, ..., Sn) {
if (S1 >= 1 && S2 >= 1 && ... && Sn >= 1) {
for (i = 1; i <= n; i++) Si--;
} else {
// 将进程插入第一个不满足Si>=1的等待队列
block();
}
}
Ssignal(S1, S2, ..., Sn) {
for (i = 1; i <= n; i++) {
Si++;
// 唤醒所有等待队列中的进程
}
}AND型信号量(同时申请多个资源)
解决的问题:进程需要同时获得多个资源时可能死锁
基本思想:一次性分配进程所需所有资源,否则一个也不分配
信号量集(扩展的AND信号量)
- 允许测试值ti ≠ 1
- 允许申请量di ≠ 1
Swait(S1, t1, d1, ..., Sn, tn, dn) {
if (S1 >= t1 && ... && Sn >= tn) {
for (i = 1; i <= n; i++) Si = Si - di;
} else {
block();
}
}
Ssignal(S1, d1, ..., Sn, dn) {
for (i = 1; i <= n; i++) {
Si = Si + di;
// 唤醒等待进程
}
}特殊情况:
Swait(S, d, d):每次申请d个资源,少于d个时不分配Swait(S, 1, 1):退化为一般记录型信号量Swait(S, 1, 0):可控开关,当S≥1时允许多个进程进入
信号量的应用
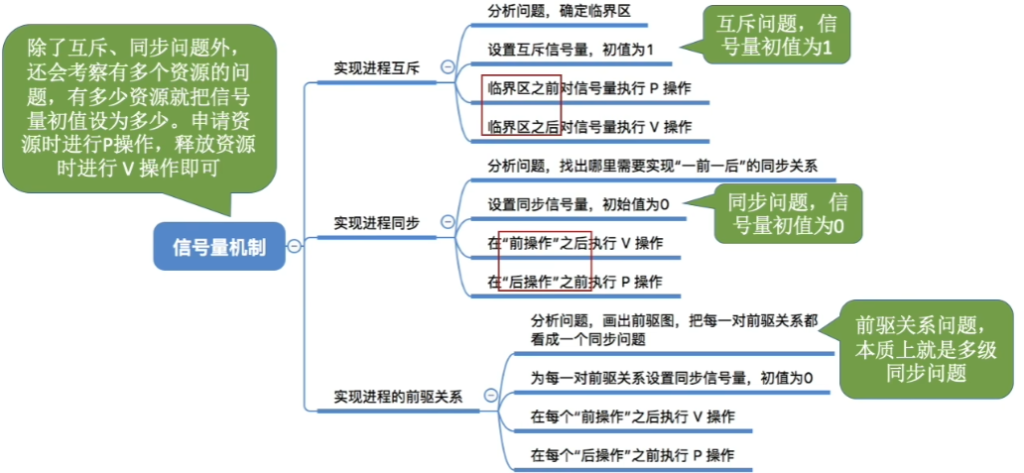
实现进程互斥
semaphore mutex = 1; // 互斥信号量,初值为1
P1(){
...
P(mutex);
// 临界区代码
...
V(mutex);
...
}
P2(){
...
P(mutex);
// 临界区代码
...
V(mutex);
...
}注意:N个进程共享资源,mutex的取值范围为[-(N-1), 1]
注意:对不同的临界资源需要设置不同的互斥信号量。
P、V操作必须成对出现。缺少P(mutex)就不能保证临界资源的互斥访问。缺少V(mutex)会导致资源
永不被释放,等待进程永不被唤醒。
实现前趋关系(进程同步)
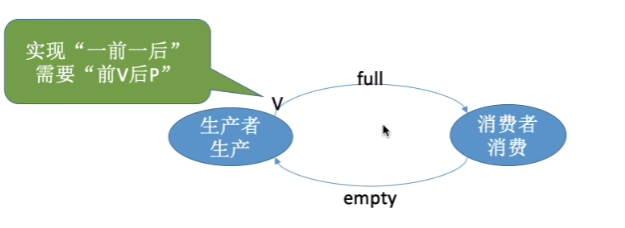
方法1:信号量表示”后继可开始” 前V后P
pseudocode
semaphore S = 0; // 初值为0
P1: ... ; V(S); // P1执行完后通知P2
P2: P(S); ... ; // P2等待P1完成方法2:信号量表示”前趋已完成”
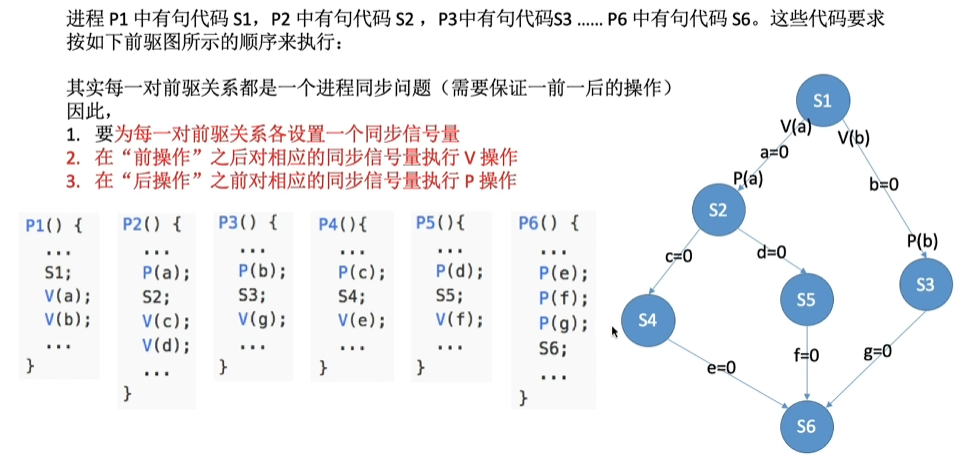
semaphore f = 0; // 初值为0
P1: ... ; V(f); // P1完成
P2: P(f); ... ; // P2等待P1完成实例:三个进程的同步
// 要求:P1→P2,P1→P3
semaphore S2 = 0, S3 = 0;
P1: ... ; V(S2); V(S3);
P2: P(S2); ... ;
P3: P(S3); ... ;经典进程同步问题
生产者-消费者问题
问题描述:
- 生产者生产产品放入缓冲区
- 消费者从缓冲区取产品消费
- 缓冲区容量有限(n个)
信号量设置:
semaphore empty = n; // 空缓冲区数量 同步信号量,表示空闲缓冲区的数量
semaphore full = 0; // 满缓冲区数量 同步信号量。表示产品的数量,也即非空缓冲区的数量
semaphore mutex = 1; // 缓冲区互斥访问 互斥信号量,实现对缓冲区的互斥访问
int in = 0, out = 0; // 缓冲区指针
item buffer[n]; // 循环缓冲区解决方案:
// 生产者进程
while (true) {
produce an item;
P(empty); // 申请空缓冲区
P(mutex); // 申请缓冲区访问权
buffer[in] = item;
in = (in + 1) % n;
V(mutex); // 释放缓冲区访问权
V(full); // 增加满缓冲区计数
}
// 消费者进程
while (true) {
P(full); // 申请满缓冲区
P(mutex); // 申请缓冲区访问权
item = buffer[out];
out = (out + 1) % n;
V(mutex); // 释放缓冲区访问权
V(empty); // 增加空缓冲区计数
consume item;
}关键要点:
- P操作顺序至关重要:必须先P(empty)再P(mutex),否则可能死锁
- 同步信号量与互斥信号量:empty/full是同步信号量,mutex是互斥信号量
- 缓冲区满/空判断:
(in+1)%n == out(满),in == out(空)
多生产者消费者问题

读者-写者问题
问题描述:
- 多个读者和写者共享数据区
- 允许多个读者可以同时对文件执行读操作;
- 不允许读者和写者同时操作,任一写者在完成写操作之前不允许其他读者或写者工作;
- 不允许多个写者同时操作,只允许一个写者往文件中写信息;
- 写者执行写操作前,应让已有的读者和写者全部退出。
第一类解法(读者优先):
可能导致”写者饿死”(持续有读者时,写者永远无法写入)
int readcount = 0; // 正在读的读者数
semaphore mutex = 1; // 保护readcount
semaphore w = 1; // 读写互斥
// 读者进程
while (true) {
P(mutex);
if (readcount == 0) P(w); // 第一个读者申请写锁
readcount++;
V(mutex);
read data; // 读操作
P(mutex);
readcount--;
if (readcount == 0) V(w); // 最后一个读者释放写锁
V(mutex);
}
// 写者进程
while (true) {
P(w);
write data; // 写操作
V(w);
}改进方案(公平策略):先来先服务
semaphore rw = 1; // 读写互斥
semaphore mutex = 1; // 保护readcount
semaphore w = 1; // 写者等待队列
int readcount = 0;
// 读者
P(w); // 申请进入等待队列
P(mutex);
if (readcount == 0) P(rw);
readcount++;
V(mutex);
V(w); // 释放等待队列
read data;
P(mutex);
readcount--;
if (readcount == 0) V(rw);
V(mutex);
// 写者
P(w);
P(rw);
write data;
V(rw);
V(w);哲学家就餐问题
问题描述:5个哲学家围坐圆桌,每人需要左右两把叉子才能就餐
基础解法(可能死锁):
semaphore fork[5] = {1, 1, 1, 1, 1};
Philosopher i:
while (true) {
think();
P(fork[i]); // 拿左叉
P(fork[(i+1) % 5]); // 拿右叉
eat();
V(fork[i]);
V(fork[(i+1) % 5]);
}死锁防止策略:
限制就餐人数:最多允许4个哲学家同时拿叉子
semaphore fork[5] = {1, 1, 1, 1, 1};
semaphore mutex = 1; // 最多4人同时就餐
P(){
while (true) {
P(mutex);
P(fork[i]);
P(fork[(i+1)%5]);
V(mutex);
eat();
V(fork[i]);
V(fork[(i+1)%5]);
think();
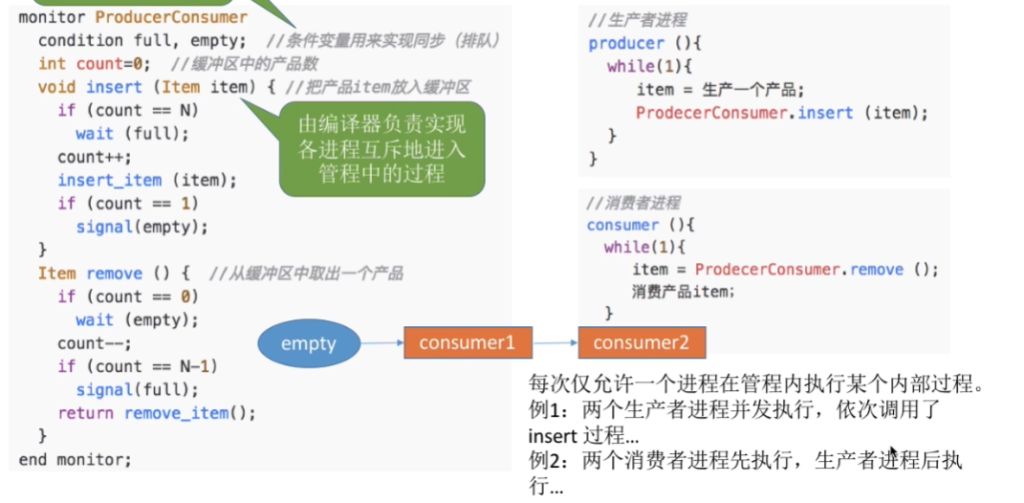
}管程机制
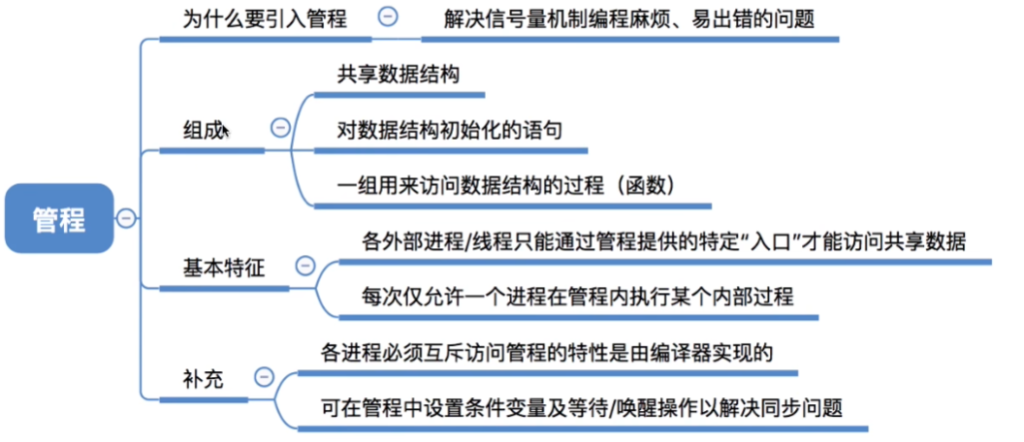
基本概念
条件变量与操作
- 条件变量:表示等待原因,每个条件变量对应一个等待队列
- 操作:
x.wait():调用进程在条件x上等待,释放管程控制权x.signal():唤醒一个在条件x上等待的进程
- Signal语义的两种处理方式:
- Hoare管程:signal后立即让出管程给等待者,等待者执行完再返回
- Mesa管程:signal仅将等待者移入就绪队列,signal进程继续执行(现代常用)
- 重要:Mesa语义中,等待者被唤醒后必须重新检查条件
利用管程解决生产者-消费者问题
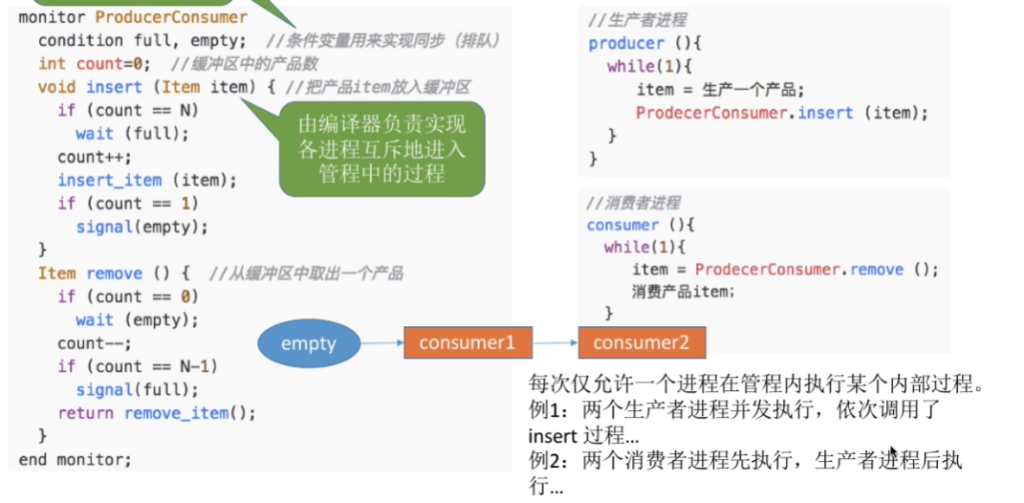
会合机制
基本概念
- 提出背景:分布式系统中无公共内存,传统同步机制难以实现
- 核心思想:进程直接通过入口调用进行同步(Ada语言的核心并发机制)
- 基本原理:
- 一个进程可以有多个入口,每个入口对应一段程序
- 进程可调用另一进程的入口
- 当调用者发出调用而对方未准备好时,调用者等待
- 当被调用者准备好而无调用者时,被调用者等待
会合的核心语句
5.7.3 利用会合解决生产者-消费者问题
-- 缓冲区管理进程
process Buffer is
buffer: array(0..max_num-1) of Item_Type;
in, out: Integer := 0;
entry Set(item: in Item_Type);
entry Get(item: out Item_Type);
begin
loop
select
when (in < out + max_num) => -- 缓冲区不满
accept Set(item: in Item_Type) do
buffer(in mod max_num) := item;
in := in + 1;
end Set;
or
when (out < in) => -- 缓冲区不空
accept Get(item: out Item_Type) do
item := buffer(out mod max_num);
out := out + 1;
end Get;
end select;
end loop;
end Buffer;
-- 生产者进程
process Producer is
item: Item_Type;
begin
loop
produce(item);
Buffer.Set(item);
end loop;
end Producer;
-- 消费者进程
process Consumer is
item: Item_Type;
begin
loop
Buffer.Get(item);
consume(item);
end loop;
end Consumer;进程通信
进程通信概念
- 定义:进程之间的信息交换
- 通信类型:
- 共享存储
- 消息传递
- 管道通信
- 客户机/服务器方式
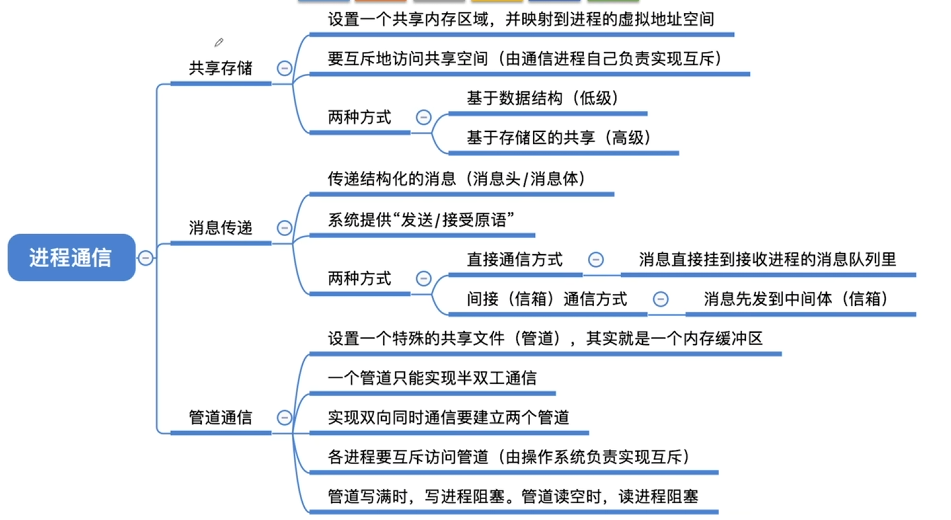
共享存储
基于共享数据结构的通信(低级)
- 进程通过公用某些数据结构交换信息
- 如:生产者-消费者问题中的有界缓冲区,P.V操作,只能传递信号,不能传递大量信息
- 缺点:同步互斥由程序员负责,易出错
基于共享存储区的通信(高级)
- 进程申请共享存储区中的一个分区
- 指定分区关键字,系统返回分区描述符
- 进程将共享存储分区连接到本进程地址空间
- 进程可直接读写该分区
- 如Send/Receive原语,能传递大量信息
- 特点:高效,但同步互斥仍需进程负责
消息传递系统
数据交换以格式化的消息为单位
- 消息头(进程ID)
- 消息体(数据)
直接通信(消息缓冲通信)
- 发送进程直接将消息发送给接收进程
- 消息挂到接收进程的消息缓冲队列
- 原语:
Send(Receiver, message)Receive(Sender, message)
间接通信(信箱通信)
- 发送进程将消息发送到信箱(中间实体)
- 接收进程从信箱中取消息
- 信箱种类:
- 私用信箱:用户进程为自己创建,单向通信
- 公用信箱:操作系统创建,双向通信
- 共享信箱:某进程创建并指明可共享
管道通信
基本概念
- 定义:用于连接读进程和写进程的共享文件(pipe文件),开辟一个大小固定的内存缓冲区
- 数据传递:以字符流形式传递大量数据
- 类型:
- 无名管道:临时,用于父子进程或兄弟进程间通信
- 有名管道(FIFO):文件系统中有名称,无亲缘关系进程也可通信
管道特点
- 只能半双工通信:数据只能单向流动(如果要双向,就需要设置两个管道)
- 先进先出:保证写入和读出的顺序一致
- 各进程要互斥地访问管道(由操作系统实现)
- 当管道写满时,写进程将阻塞,直到读进程将管道中的数据取走,即可唤醒写进程。
- 当管道读空时,读进程将阻塞,直到写进程往管道中写入数据,即可唤醒读进程
- 无界性:理论上可传输任意长度数据
- 内核缓冲区:数据在内核缓冲区中,不是在外存
- 管道中的数据一旦被读出,就彻底消失。因此,当多个进程读同一个管道时,可能会错乱。对此,通常有两种解决方案:
- ①一个管道允许多个写进程,一个读进程
- ②允许有多个写进程,多个读进程,但系统会让各个读进程轮流从管道中读数据(Linux的方案)。
管道与消息队列的区别
| 特性 | 管道 | 消息队列 |
|---|---|---|
| 数据形式 | 字节流 | 结构化消息 |
| 边界 | 无消息边界 | 有消息边界 |
| 容量 | 内核缓冲区大小限制 | 系统限制 |
| 通信关系 | 常用于亲缘进程 | 任意进程 |
| 持久性 | 随进程结束消失 | 可持久化 |
线程技术
线程的引入
进程的局限性
- 进程作为资源拥有者和调度单位
- 创建、撤销、切换开销大
- 限制了并发程度的进一步提高
线程的概念
- 定义:进程中的一个实体,是被系统独立调度和分派的基本单位
- 线程属性:

线程与进程的比较
| 比较维度 | 进程 | 线程 |
|---|---|---|
| 调度基本单位 | 传统OS中是 | 引入线程后是 |
| 并发性 | 进程间可并发 | 进程内线程间也能并发 |
| 拥有资源 | 资源拥有的独立单位 | 基本不拥有系统资源 |
| 独立性 | 进程间相对独立 | 进程内线程间独立性差 |
| 系统开销 | 创建、撤销、切换开销大 | 创建、撤销、切换开销小 |
| 同步通信 | 复杂(需IPC) | 简单(共享地址空间) |
| 多处理机支持 | 一个进程只能分一个处理器 | 一个进程可分多个处理器 |
| 数据/代码段 | 每个进程独立 | 同一进程的线程共享 |
| 堆栈 | 每个进程独立 | 每个线程独立 |
线程的实现方式
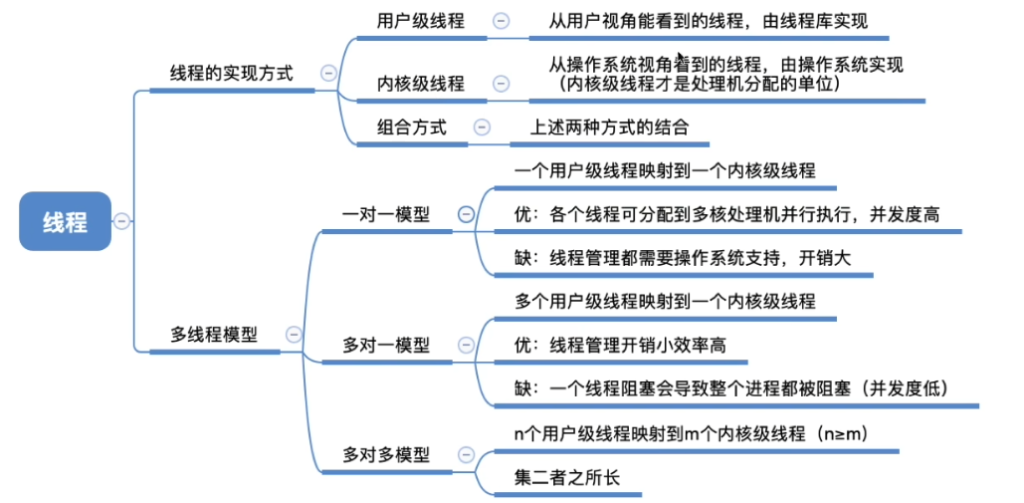
用户级线程(User-Level Thread, ULT)
- 管理方式:由应用程序通过线程库管理,内核不知晓
- 线程库功能:创建、撤销、同步、调度线程
- 优点:
- 线程切换不需内核介入,速度快
- 调度算法可由应用程序定制
- 可运行在任何OS上(只需线程库)
- 缺点:
- 一个线程阻塞会导致整个进程阻塞(所有线程被阻塞)
- 不能利用多处理机优势(内核以进程为单位分配CPU)
内核级线程(Kernel-Level Thread, KLT)
- 管理方式:由操作系统内核直接管理
- 优点:
- 可调度同一进程的多个线程到不同处理器
- 一个线程阻塞不影响进程内其他线程
- 内核支持,功能强大
- 缺点:
- 线程切换需要内核介入,开销大
- 用户态到内核态切换频繁
线程应用实例:Web服务器
多线程Web服务器架构
网络请求
↓
[ 分派线程 Dispatcher ]
↓
+----------+----------+
↓ ↓ ↓
[工作线程] [工作线程] [工作线程]
↓ ↓ ↓
Web缓存 ←→ 磁盘I/O ←→ 客户端响应
线程分工
- 分派线程:
- 接收客户端请求
- 将请求分派给空闲工作线程
- 维护工作线程池
- 工作线程:
- 检查Web页面缓存
- 若缓存命中,直接返回页面
- 若缓存未命中,从磁盘读取页面
- 将页面返回客户端
性能分析
- 单线程服务器:顺序处理请求,I/O阻塞时CPU空闲
- 多线程服务器:一个线程I/O阻塞时,其他线程可继续处理请求
- 性能提升:假设
- 处理请求:15ms(缓存命中)
- 磁盘I/O:75ms(额外,1/3概率需要)
- 多线程可显著提高吞吐量
线程相关问题
为什么每个线程必须有独立的堆栈?
- 保存局部变量:函数调用时的局部变量
- 保存返回地址:函数调用返回位置
- 保存寄存器现场:线程切换时需要
- 独立性:保证线程执行流的独立性
用户级与内核级线程对比总结
| 特性 | 用户级线程(ULT) | 内核级线程(KLT) |
|---|---|---|
| 实现位置 | 用户空间 | 内核空间 |
| 管理方式 | 应用程序 | 操作系统 |
| 切换速度 | 快(无需内核介入) | 慢(需要内核介入) |
| 阻塞影响 | 整个进程阻塞 | 只阻塞该线程 |
| 多处理器利用 | 不能 | 能 |
| 可移植性 | 好(只需线程库) | 差(依赖OS支持) |
| 调度控制 | 应用程序控制 | 操作系统控制 |
综合问题与思考
同步问题综合
仓库问题
问题:仓库存放A和B两种产品,要求:
- 每次只能存入一种产品
- -N < A产品数量 – B产品数量 < M
解决方案:
semaphore Sa = M - 1; // 允许A比B多入库的数量
semaphore Sb = N - 1; // 允许B比A多入库的数量
semaphore mutex = 1; // 仓库互斥
// A产品入库
while (true) {
P(Sa); // 检查能否再存A
P(mutex);
// 存入A产品
V(mutex);
V(Sb); // B可存数增加
}
// B产品入库
while (true) {
P(Sb); // 检查能否再存B
P(mutex);
// 存入B产品
V(mutex);
V(Sa); // A可存数增加
}进程同步中的常见问题
死锁(Deadlock)
- 条件:互斥、占有并等待、不可抢占、循环等待
- 预防:破坏四个必要条件之一
- 避免:银行家算法
- 检测与恢复:资源分配图、进程回滚
饿死(Starvation)
- 定义:进程长期得不到所需资源,无法继续执行
- 例子:读者-写者问题中写者可能饿死
- 解决方案:公平调度算法、优先级老化
优先级反转(Priority Inversion)
- 现象:低优先级进程持有高优先级进程所需资源
- 解决方案:优先级继承、优先级天花板
现代操作系统中的进程管理
Linux进程管理特点
- 进程与线程统一:使用task_struct表示,线程是共享资源的进程
- 命名空间:进程隔离,容器技术基础
- 控制组(cgroups):资源限制和统计
- 实时调度:SCHED_FIFO、SCHED_RR策略
RISC-V架构与操作系统
- 星光(BeagleV):基于RISC-V的开源单板计算机
- 意义:降低RISC-V开发门槛,促进国产芯片生态
多核与分布式系统中的进程管理
- 多核调度:负载均衡、缓存亲和性
- 分布式同步:时钟同步、分布式锁、共识算法
- 微内核架构:将操作系统功能移至用户空间
九、关键概念总结
进程通信方式比较
| 通信方式 | 实现机制 | 同步需求 | 适用场景 |
|---|---|---|---|
| 共享内存 | 映射到进程地址空间 | 需要显式同步 | 高性能,大数据量 |
| 消息传递 | 内核缓冲区中转 | 系统提供同步 | 分布式系统,松耦合 |
| 管道 | 内核缓冲区字节流 | 系统提供同步 | 亲缘进程,简单通信 |
| 套接字 | 网络协议栈 | 系统/应用同步 | 网络通信,跨机器 |
第九章:分页系统设计问题
9.1 共享页面深入
9.1.1 共享实现方式
- 代码共享:
- 只读页面可安全共享
- 多个进程页表指向相同物理帧
- 示例:系统库、公共代码
- 数据共享:
- 需要同步机制
- 写时复制技术:
a. 初始共享只读副本
b. 写操作触发页面复制
c. 每个进程有自己的可写副本
- fork()中的共享:
- Unix fork:父子进程共享相同地址空间
- 写时复制优化:实际复制延迟到写入时
9.1.2 共享管理问题
- 引用计数:跟踪共享页面被多少进程使用
- 回收策略:所有进程释放后才回收页面
- 一致性:确保共享页面内容一致性
9.2 清除策略优化
9.2.1 分页守护进程
- 作用:定期检查并清理页面
- 工作方式:
- 睡眠大部分时间
- 定时唤醒检查内存状态
- 空闲页过少时启动页面清理
9.2.2 双指针时钟算法
- 前指针:分页守护进程控制,清理脏页面
- 后指针:页面置换使用,标准时钟算法
- 优点:提高后指针找到干净页面的概率
9.2.3 页面缓冲技术
- 干净页面链表:可直接重用
- 脏页面链表:需要写回磁盘
- 空闲页面阈值:保持一定数量空闲页
9.3 页面锁定机制
9.3.1 需要锁定的场景
- I/O操作中页面:避免DMA访问时页面被换出
- 内核关键页面:操作系统核心代码和数据
- 实时任务页面:保证实时性
9.3.2 实现方式
- 页表锁定位:防止页面被置换
- 内核缓冲区:I/O先到内核缓冲区,再复制到用户空间
- 临时锁定:I/O期间锁定,完成后释放
9.4 后备存储管理
9.4.1 交换区组织方式
- 静态分配:
- 进程创建时分配固定大小交换区
- 管理简单,地址计算容易
- 可能浪费空间
- 动态分配:
- 页面换出时分配磁盘空间
- 空间利用率高
- 管理复杂,需要记录每个页面的磁盘位置
9.4.2 交换区优化
- 分离存储:代码、数据、栈分开管理
- 预分配预留:避免频繁分配
- 集群分配:相邻页面分配连续磁盘空间
9.5 其他设计问题
9.5.1 分离指令和数据空间
- I-space和D-space:独立地址空间
- 优点:
- 便于共享只读代码
- 独立保护机制
- 支持更大地址空间
- 实现:两个页表,独立管理
9.5.2 大页支持
- 目的:减少TLB失效,提高性能
- 大小:2MB、1GB等
- 应用:数据库、科学计算等
9.5.3 反置页表优化
- 哈希加速:虚拟地址→物理地址快速映射
- 链式冲突解决:哈希冲突时链表连接
- TLB配合:频繁访问页面通过TLB加速
第十章:请求分段系统
10.1 段表扩展字段
| 字段 | 功能 | 说明 |
|---|---|---|
| 存在位 | 段是否在内存 | 1位 |
| 访问权限 | 读/写/执行 | 2-3位 |
| 修改位 | 段是否被修改 | 1位 |
| 访问位 | 访问频率/时间 | 若干位 |
| 外存地址 | 段在磁盘位置 | 磁盘地址 |
| 增长方向 | 段增长方向 | 1位(栈/堆) |
| 段长限制 | 最大允许长度 | 长度值 |
10.2 缺段中断处理
10.2.1 处理流程
- 检查内存空间:是否有足够连续空间
- 空间足够:直接装入
- 空间不足:
a. 检查能否通过紧凑获得空间
b. 若不能,淘汰一个或多个段
c. 执行紧凑(如果需要) - 装入段:从外存读入段
- 更新段表:设置存在位和基址
10.2.2 与缺页中断对比
- 单位不同:段 vs 页
- 空间要求:需要连续空间 vs 任意位置
- 置换粒度:整个段 vs 单个页面
- 发生频率:较低 vs 较高
10.3 分段共享详细
10.3.1 共享段表管理
text复制下载
共享段表项结构: 1. 段名/标识符 2. 段长 3. 内存基址 4. 共享进程计数 5. 进程引用列表 6. 其他管理信息
10.3.2 共享过程示例
text复制下载
进程A首次访问段S: 1. 检查共享段表,S不存在 2. 为S分配内存空间 3. 从磁盘装入S 4. 创建共享段表项,count=1 5. 更新进程A段表指向S 进程B访问段S: 1. 检查共享段表,S存在 2. 更新进程B段表指向S 3. count++ 进程A释放段S: 1. 从进程A段表移除S引用 2. count-- 3. 若count=0,释放S内存
10.3.3 共享同步问题
- 只读共享:无同步问题
- 可写共享:需要同步机制
- 互斥访问
- 版本控制
- 事务支持
10.4 分段保护机制
10.4.1 越界保护
- 段长检查:偏移量 < 段长
- 增长方向:栈段向下增长需特殊处理
- 越界处理:触发段错误(Segmentation Fault)
10.4.2 权限保护
- 基本权限:读(R)、写(W)、执行(X)
- 组合权限:RW、RX、RWX等
- 权限违反:触发保护异常
10.4.3 环保护机制
- 特权级别:通常0-3级,0为最高
- 访问规则:
- 高级别可访问低级别数据
- 低级别不能访问高级别数据
- 调用门机制控制跨级别调用
- 现代实现:用户态(3) vs 内核态(0)
10.5 分段系统优缺点总结
10.5.1 优点
- 逻辑结构清晰:符合程序设计习惯
- 易于共享:以段为单位共享
- 动态链接支持:运行时链接模块
- 动态增长:数据段、栈段可扩展
- 保护粒度细:段级别保护
- 便于调试:地址有逻辑意义
10.5.2 缺点
- 外部碎片:内存空间不连续
- 管理复杂:需要紧凑和碎片整理
- 内存利用率:可能较低
- 交换开销:整个段交换,即使只使用部分
- 实现复杂:硬件和软件支持复杂
10.5.3 适用场景
- 需要动态链接:如现代操作系统
- 需要精细保护:安全敏感应用
- 逻辑结构重要:大型复杂软件
- 共享需求多:多进程协作应用
总结与展望
存储管理技术演进
| 发展阶段 | 主要技术 | 特点 | 解决的问题 |
|---|---|---|---|
| 早期 | 单一连续 | 简单 | 基本存储管理 |
| 多道初期 | 固定分区 | 支持多道 | 内存分配 |
| 多道发展 | 动态分区 | 灵活分配 | 提高利用率 |
| 现代基础 | 分页 | 离散分配 | 外部碎片 |
| 逻辑管理 | 分段 | 逻辑组织 | 共享保护 |
| 综合方案 | 段页式 | 结合优点 | 全面需求 |
| 虚拟化 | 虚拟存储 | 逻辑扩充 | 大程序运行 |
技术趋势
- 大页支持:减少TLB压力,提高性能
- NUMA优化:非均匀内存访问架构优化
- 内存压缩:减少交换开销
- 透明大页:自动管理大页,减少碎片
- 异构内存:DRAM与非易失内存混合使用
- 内存去重:相同页面只保存一份副本
实际应用建议
- 通用系统:请求分页 + Clock类算法
- 服务器:考虑大页和NUMA优化
- 嵌入式:简单分页或静态分区
- 实时系统:锁定关键页面,保证确定性
- 安全系统:强化分段保护,隔离敏感数据
性能调优关键
- 缺页率监控:系统健康的重要指标
- 工作集分析:合理分配物理内存
- 置换算法选择:根据负载特性选择
- 页面大小优化:平衡内部碎片和TLB效率
- 预读策略:利用局部性提前加载